Database Performance Tuning and Query Optimization
Database Performance Tuning and Query Optimization¶
Performance Tuning Concepts¶
- database performance tuning: A set of activities and procedures designed to reduce the response time of a database system that is, to ensure that an end user query is processed by the DBMS in the minimum amount of time.
Performance Tuning Client and Server¶
- Most performance tuning focuses on minimizing I/O operations.
Client Side¶
- SQL Performance Tuning: Generate optimal SQL queries to get the correct answer in least amount of time using the minimum server resources.
Server Side¶
- DBMS Performance Tuning: Address client requests as quickly as possible while optimizing compute resources.
DBMS Architecture¶
- Data Files: One of, generally, several files in a DBMS that stores a databases data: rows, tables, indexes, etc.
- Extent: Predefined data-file expansion increment.
- Table Space/File Group: Logically grouped data files. Common table spaces are: System (i.e. data-dictionary), user data, indexes, temporary (sorts & grouping).
- data cache/buffer cache: Reserved memory area caching sys-catalog, indexes, and read/write data.
- SQL cache/Procedure cache: Reserved memory area storing processed recent SQL queries, stored procedures, triggers, and functions.
- I/O Request: Reads/Writes data from data-cache to physical device in blocks of powers of 2.
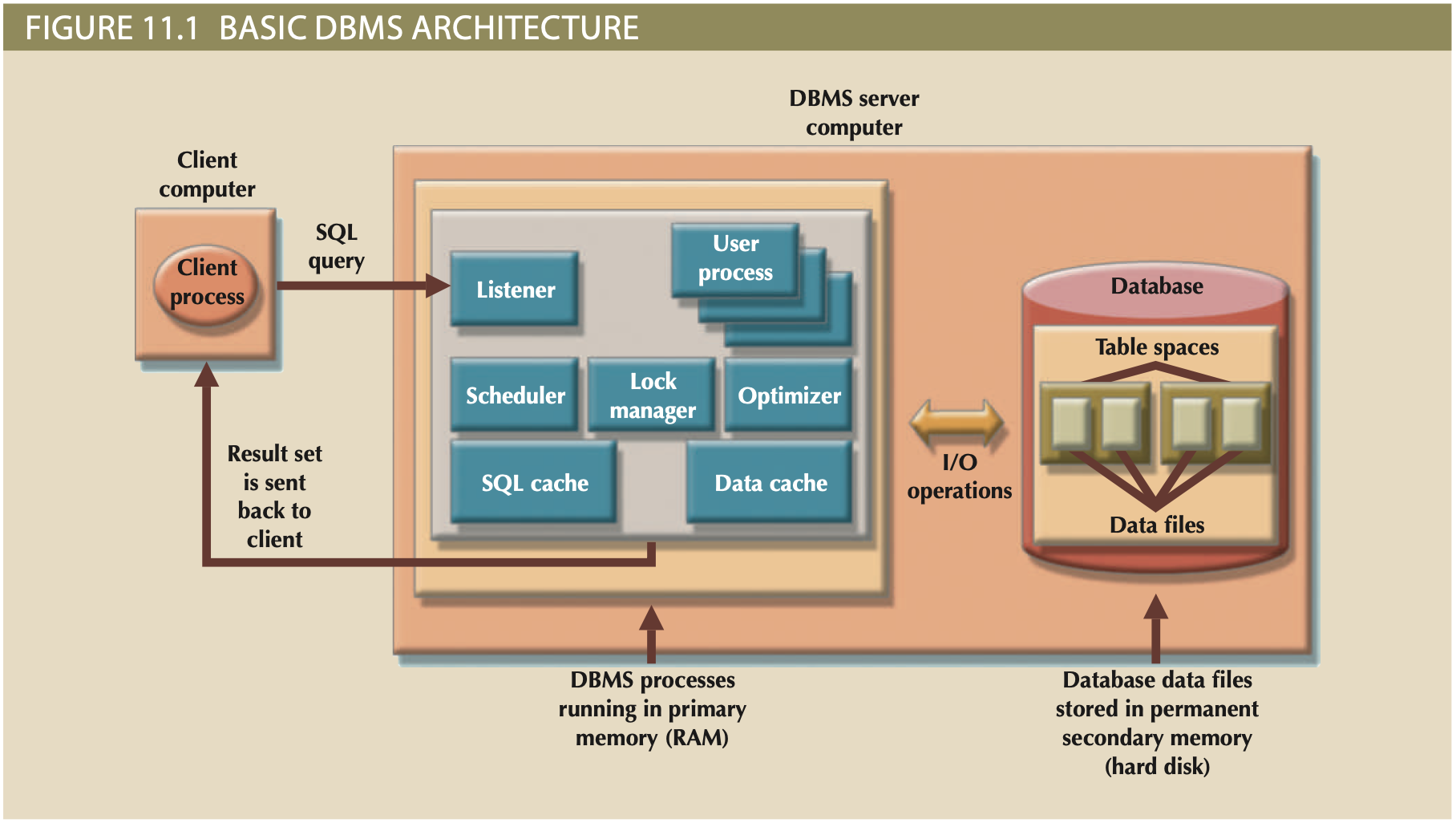
- Listener: Handles processing of client requests.
- User: User process per client.
- Scheduler: Organizes concurrent requests.
- Optimizer: Analyzes SQL and optimizes data access.
Database Query Optimization Modes¶
2 Principles of Query Optimization¶
- Optimum execution order for fastest exec time
- Optimum site selection to minimize I/O and communication time.
Classification of Query Optimization Algorithms/Modes¶
- Classification by Order:
- Automatic Query Optimization: DBMS finds most efficient access path (favored, but at the expense of CPU usage).
- Manual query Optimization: End user finds most efficient access path
- Classification by Timing of Optimizations
- Static Query Optimization: Access path is predetermined at compile time (i.e. in code like C#)
- Dynamic Query Optimization: Access path is determined at run-time using most up-to-data info about the RDBMS.
- Classification by Info Type
- Statistically Based Query Optimization: Statistically info about database is used to determine access path.
- Dynamic Statistical Generation Mode: DBMS automatically updates database access and statistics.
- Manual Statistical Generation Mode: DBA must periodically run a routine to generate data access statistics.
- Rule-Based Query Optimization: Preset rules by DBA or End-User dictate access path.
- Statistically Based Query Optimization: Statistically info about database is used to determine access path.
Database Statistics¶
- Include statistics on: # CPUs, CPU Speed, Temp Space Avail., # rows, # disk blocks used, Max/Avg row length, # Cols/Row,
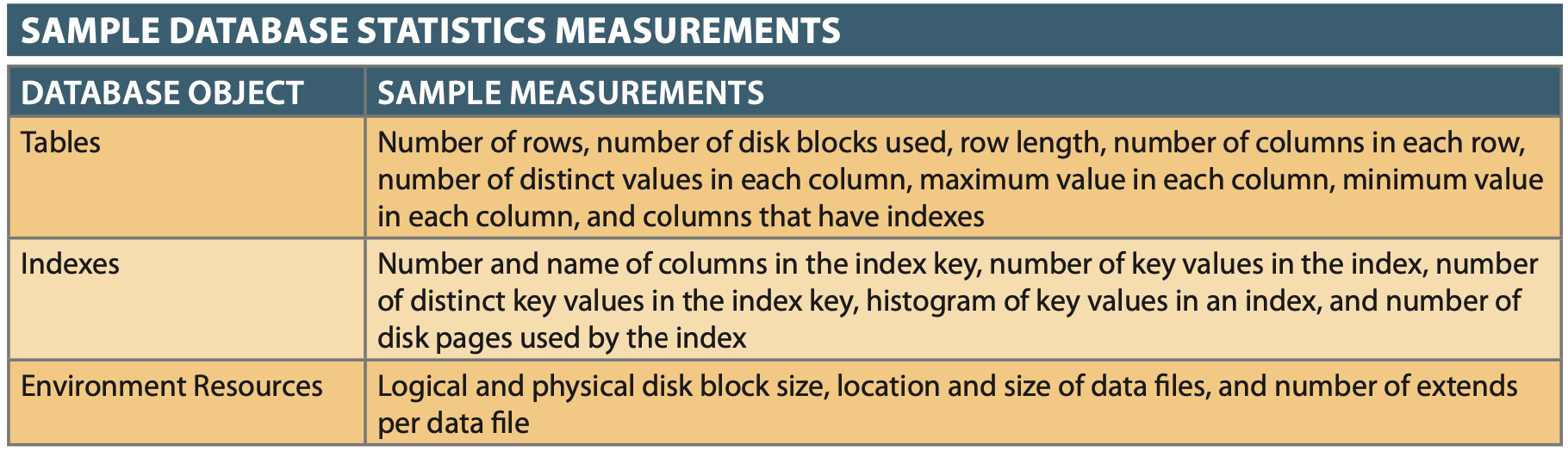
- Provides a snapshot of DB characteristics.
- Can be gathered manually or automatically (ANALYZE command gathers stats)
- Oracle: ANALYZE
- MySQL: ANALYZE TABLE
;
- DB2: RUNSTATS
- SQL Server: UPDATE STATISTICS
] Query Processing¶
3 Phases of Query Processing¶
- Parsing: Parses SQL and chooses most efficient execution plan.
- Execution: Executes query based on chosen plan.
- Fetching: Fetches data and returns result set.
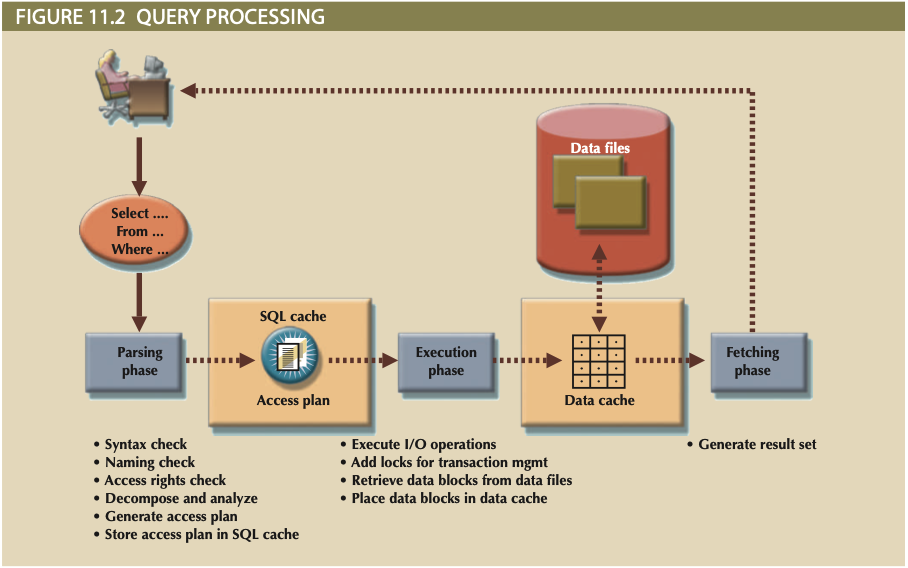
Note
Processing DDL (Create, etc.) is different then processing DML (SELECT, INSERT, UPDATE, DELETE as DML deals with user data while DDL changes the schema/system catalog.
SQL Parsing Phase¶
- Query Optimizer: DBMS process that parses query and optimizes data access path.
- Steps of Query Optimizer:
- Validate SQL syntax
- Validate SQL against Data Dictionary for table/column objects
- Validate User Access Rights via Data Dictionary
- Break SQL into atomic parts.
- Optimize SQL to equivalent faster query
- Prepare SQL for execution with efficient access plan
- Steps of Query Optimizer:
- Access/Execution Plan: Compilation time plan that determines how an application query will access the database at run-time
- If the Access Plan exists in SQL Cache, DBMS will re-use plan to save time.
- If not in cache, optimizer will:
- Evaluate plans and pick indexes for optimal join operations
- Places the chosen plan into the SQL Cache
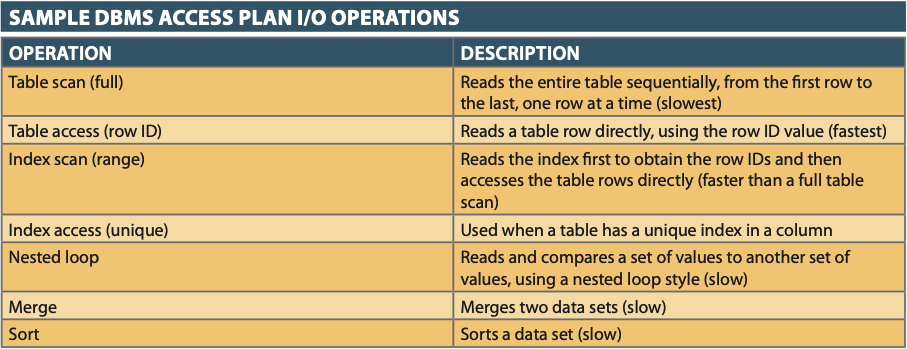
SQL Execution Phase¶
- All I/O operations in Execution Plan are executed, and proper locks are acquired for data access.
- Resulting data is stored in the DBMS data cache
- Rows matching conditions, order bys, grouping are completed
- Transaction commands are completed during SQL Parsing Phase and SQL Execution Phase.
SQL Fetching Phase¶
- Facilitates migrating data from server cache to client cache.
- Temporary table space may be used to allow clients to fetch data in batches.
Query Processing Bottlenecks¶
- The more complex a query, the higher chance of a query processing bottleneck
- The more complex a system and the tighter coupled components, the higher chance of a component bottleneck
Typical Bottlenecks and Performance Recommendations¶
- CPU: Match CPU to workload
- High CPU utilization could mean a mismatch between CPU and workload
- Could also mean not enough of another component like RAM (swapping?).
- RAM: SQL Cache, Data Cache, DBMS processes, and OS compete for RAM, so it should be right-sized dependent on system and database purpose.
- Hard Disks: Slow disks can bottleneck performance, so match HD Speed and I/O transfer rates to desired workload performance.
- Faster Disks, such as SSDs, can offset some of the RAM bottlenecks via Virtual Memory
- Network: Network congestion (i.e. network demand exceeds capacity) can cause bottlenecks.
- Use QoS to grant application priority.
- Limit the number of clients on the network.
- Limit the network to just qualified applications.
- Application Code: Poorly designed DBs and Poorly designed code often cause bottlenecks.
- Write applications that Lazy load data
- Optimize or eliminate AdHoc Queries
- Apply code optimization techniques.
- Redesign poorly architected databases
Indexes and Query Optimization¶
Note
The purpose of indexes is to speed up access to specific rows in large tables. So why not index everything? First, indexes also consume space, so space constraints can limit index usage. Further, indexing every column can harm the query optimizer performance by forcing it to analyze more index options while building its query plan. Third, low Data Sparsity, which refers to the range of values in a column, can make indexes moot since they contain a relatively small number of keys to a large subset of rows. High Data Sparsity columns, on the other hand, are ideal candidates for indexes.
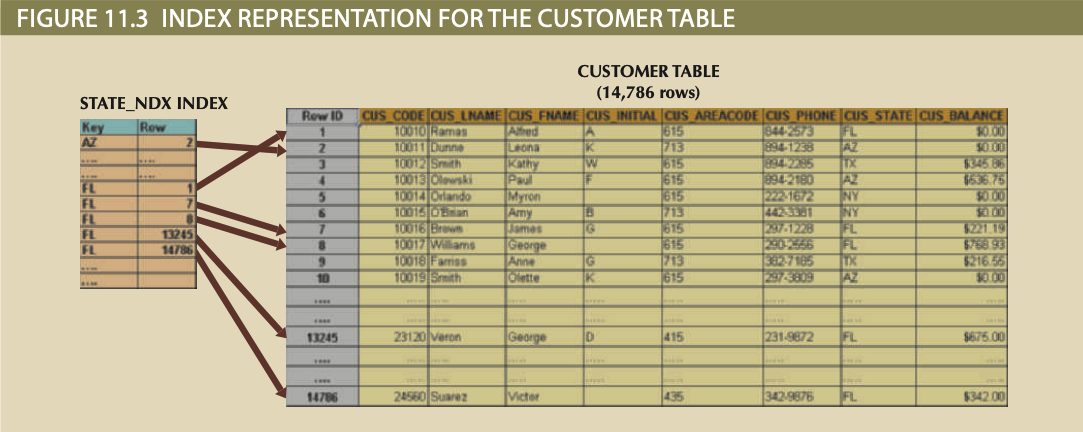
Index Data Structures¶
- Hash Index: Simple and fast lookups via a key that is hashed into a value that points to matching database rows. Great for indexes hitting equality conditions.
- B-tree Index: Auto-balancing data-structure, where the leaf nodes contain pointers to the data rows. Most common index, and is great for high sparsity data.
- Bitmap Index: Index suited best for low sparsity data, and is represented by BIT Arrays, where each BIT represents if the row pointed to meets a condition. Very low space usage.
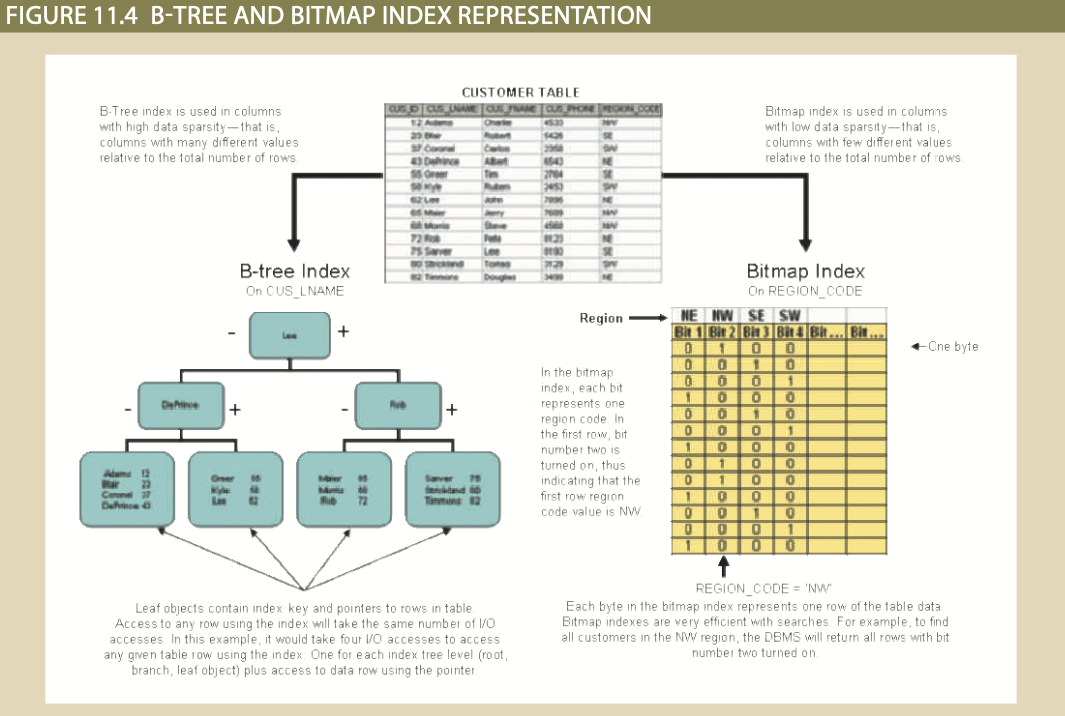
Optimizer Choices¶
Note
SQL Parsing is performed by a query optimizer and decides which indexes to use, the order of table joins, how to perform those joins, and more.
Optimizer Algorithms¶
- Rule-based Optimizer: Decides how to execute a query by assigning fixed costs via preset rules (e.g. costs are based off of full-table-scans, PK/Index matches, etc.)
- Cost-based Optimizer: Decides query execution through algorithmic analysis of statistics about various DB objects (e.g. num-rows, num-columns, I/O speed, RAM, etc.)
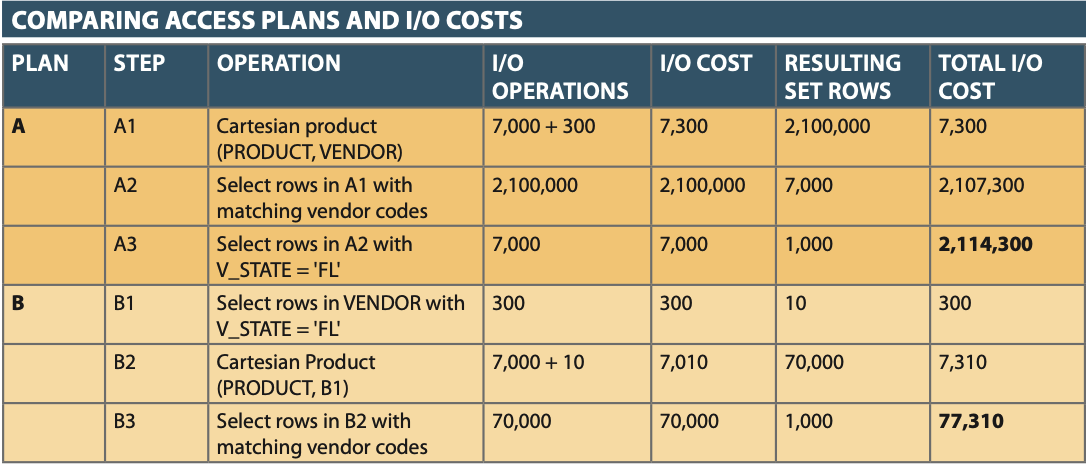
Optimizer Hints¶
- Optimizer Hints: Are special instructions end-users can add to SQL queries to alter how the query optimizer decides to execute a query.

SQL Performance Tuning¶
Note
Most current RDBMS already do a solid job of query optimization, but its still a good idea to help it out and limit the server-side processing. With that said, most techniques are RDBMS specific.
Index Selectivity¶
- Using indexes is the #1 step in performance optimization.
- Most useful for culling a small subset of rows from a large table.
- Too many indexes slow down INSERT, UPDATE, and DELETE operations.
- So when are they used?
- When an Indexed column appears alone in WHERE or HAVING clause.
- When an Indexed column appears alone in GROUP BY or ORDER BY clause.
- When a MAX/MIN function wraps and Indexed column.
- When an Indexed column has high data sparsity
- So how do we increase the likelihood of index use (i.e. HIGH Index Selectivity)
- Create indexes for each single attribute commonly used in a WHERE, HAVING, GROUP BY, or ORDER BY clause.
- Avoid indexes on small tables or tables with low data sparsity.
- Always declare PK and FK to coerce join operations to use Indexes
- Create indexes on non-PK/FK columns commonly used in joins
- When the RDBMS supports it (Oracle, SQL Server, DB2) use function-based indexes (i.e. indexes on derived types or types with functions in them) that are commonly used in reports.
Conditional Expressions¶
- Typically in the WHERE or HAVING clauses.
- So how can we format conditional expressions to help the query optimizer?
- Use simple columns or literals as operands in a conditional expression.
- Numeric field comparisons are faster than character, date, and NULL comparisons.
- Equality comparisons are generally faster than inequality comparisons.
- Whenever possible, transform conditional expressions to use literals (i.e. remove/simplify Math or derived parts of query if possible)
- When using multiple conditional expressions, write the “=” conditions first.
- Short Circuit Logic Conditions:
- If you use multiple AND conditions, write the condition most likely to be false first.
- When using multiple OR conditions, put the condition most likely to be true first.
- Whenever possible, try to avoid the use of the NOT logical operator.
Query Formulation¶
- Step to Formulate our Queries
- Identify columns and computations required
- Simple expressions?
- Aggregate functions?
- Granularity? (i.e. should you use sub-queries and or views)
- Identify Source Tables
- Determine PK/FK or other attribute table joins.
- Determine criteria
- Simple WHERE?
- Compared to a list of values? (i.e. IN is needed)
- Nested comparisons?
- Grouped Data?
- Determine order
- Identify columns and computations required
DBMS Performance Tuning¶
Server Side Tuning¶
(See above for what’s stored in each Cache)
- Size the data cache appropriately
- Size the SQL Cache appropriately
- Size the sort/ordering cache
- Decide which Optimizer mode is best suited Rule or Cost.
- Store as much of DB in primary memory as possible to minimize I/O
- Some DBs are fully In-Memory Databases
- Use I/O Accelerators
- SSD drives
- RAID sets (Redundant Array of Independent Disks)
- Minimize Disk Contention
- Put Sys-Tables on own volume
- Balance performance and usability by splitting up User Data Table Spaces
- Put high-usage tables on own volume.
- Create unique Index Table Space per application or user group.
- Put on own volumes if possible
- Create unique Temporary Table Space per application or user group.
- Put on own volumes if possible
- Use Oracle Index-organized tables or SQL Server Clustered Index Tables to help organize table spaces.
- Use Table Partitioning by attribute if available.
- Denormalize, but only when appropriate.
- Store derived columns in tables when appropriate.
- Oracle: ANALYZE